Appearance
复现国盛《基金重仓股研究》Phase 1 · 因子检验 · notebook 版
复现报告核心:基金重仓股的持仓因子对其远期超额收益的预测力(IC / ICIR / 分层)。
- 数据:tushare
fund_portfolio(一季报+三季报前十大重仓,全样本聚合)→ 持仓面板;个股复权价;沪深300。 - 因子:
Topten_to_float_ashare=Σ基金持有市值/流通市值;delta=其环比变化;Topten_count=重仓基金数。 - 预测目标:市场超额(个股 − 沪深300)近似报告的残差收益(未做风格/行业剥离)。
- 频率:半年频(随 Q1/Q3 披露),对每个披露期(季末+约 35 天的首个交易日)用持仓因子预测到下一披露期的超额收益。
仅供研究学习,不构成投资建议。脚本版见
scripts/replicate_fund_factor.py,口径见scripts/fund_holdings_panel.py。
python
%matplotlib inline
import os
while not os.path.exists("pyproject.toml") and os.getcwd() != "/":
os.chdir("..")
import numpy as np, pandas as pd, matplotlib, matplotlib.pyplot as plt
from matplotlib import font_manager
for _n in ["PingFang SC", "Hiragino Sans GB", "Arial Unicode MS", "Songti SC"]:
if _n in {f.name for f in font_manager.fontManager.ttflist}:
matplotlib.rcParams["font.sans-serif"] = [_n]; break
matplotlib.rcParams["axes.unicode_minus"] = False
from quant.reports.metrics import annualized_return, sharpe_ratio, max_drawdown # 内核:绩效原语
PPY = 2 # 半年频
panel = pd.read_parquet("data/raw/fund_holdings_panel.parquet") # 持仓面板(缓存)
pxdf = pd.read_parquet("data/raw/fund_factor_px.parquet") # 个股复权价(缓存)
idx = pd.read_parquet("data/raw/fund_factor_hs300.parquet").set_index("trade_date")["close"] # 沪深300(缓存)
px = pxdf.pivot(index="trade_date", columns="ts_code", values="adjclose")
periods = sorted(panel["period"].unique())
# 调仓日 = 季末+~35天后首个交易日;px.index 恰为这些 rb 日,据此复原 period→rb 映射(离线无需日历)
rb_index = list(px.index)
def rb_date(period):
target = (pd.to_datetime(period) + pd.Timedelta(days=35)).strftime("%Y%m%d")
after = [d for d in rb_index if d >= target]
return after[0] if after else None
p2rb = {p: rb_date(p) for p in periods}
p2rb = {p: d for p, d in p2rb.items() if d is not None}
periods = [p for p in periods if p in p2rb]
print("价格面板:%d 调仓日 × %d 股票" % (px.shape[0], px.shape[1]))
print("披露期数:", len(periods), " 从", periods[0], "到", periods[-1])价格面板:19 调仓日 × 4000 股票
披露期数: 19 从 20110331 到 20200331
构造(期 × 股)样本:因子 → 到下一期的市场超额
python
recs = []
for p, p1 in zip(periods[:-1], periods[1:]):
d0, d1 = p2rb[p], p2rb[p1]
if d0 not in px.index or d1 not in px.index or d0 not in idx.index or d1 not in idx.index:
continue
sub = panel[panel["period"] == p].set_index("symbol")
codes = [c for c in sub.index if c in px.columns]
r = px.loc[d1, codes] / px.loc[d0, codes] - 1.0
exc = r - (idx.loc[d1] / idx.loc[d0] - 1.0) # 市场超额
df = pd.DataFrame({"fac_tofloat": sub.loc[codes, "fac_tofloat"],
"delta_tofloat": sub.loc[codes, "delta_tofloat"],
"cnt": sub.loc[codes, "cnt"], "exc": exc.values}).dropna(subset=["exc"])
df["period"] = p
recs.append(df)
data = pd.concat(recs)
print("有效(期×股)样本:", len(data), " 覆盖期数:", data["period"].nunique())有效(期×股)样本: 21454 覆盖期数: 18
因子检验:RankIC / ICIR / 分层
每个截面对因子与远期超额做 Spearman 相关(RankIC),分 10 层取各层平均超额,再算多头(最高组)与多空(高−低)的年化/回撤/夏普。
python
def evaluate(factor_col, n=10):
ics, layer = [], {q: [] for q in range(n)}
for p, g in data.groupby("period"):
g = g.dropna(subset=[factor_col])
if len(g) < 50:
continue
ics.append(g[factor_col].corr(g["exc"], method="spearman"))
qcut = pd.qcut(g[factor_col].rank(method="first"), n, labels=False)
for q in range(n):
layer[q].append(g["exc"][qcut == q].mean())
ic = pd.Series(ics)
icir = ic.mean() / ic.std() * np.sqrt(PPY)
nav = {q: np.cumprod([1 + x for x in layer[q] if not np.isnan(x)]) for q in range(n)}
top = pd.Series([x for x in layer[n - 1] if not np.isnan(x)])
ls = pd.Series([a - b for a, b in zip(layer[n - 1], layer[0])]).dropna()
stat = dict(ic=ic.mean(), icir=icir, icpos=(ic > 0).mean(),
top_ann=annualized_return(top, PPY), top_mdd=max_drawdown(top), top_sharpe=sharpe_ratio(top, PPY),
ls_ann=annualized_return(ls, PPY), ls_mdd=max_drawdown(ls), ls_sharpe=sharpe_ratio(ls, PPY))
return icir, nav, stat
NAMES = {"fac_tofloat": "Topten_to_float_ashare(持仓/流通市值)",
"delta_tofloat": "delta_to_float_ashare(环比变化)",
"cnt": "Topten_count(重仓基金数)"}
results, stats = {}, {}
print("=== 因子检验(预测目标=市场超额, 半年频) ===")
for col, name in NAMES.items():
icir, nav, stat = evaluate(col)
results[col] = (nav, name); stats[col] = stat
print("\n[%s]" % name)
print(" RankIC %.3f | ICIR %.2f | IC>0占比 %.0f%%" % (stat["ic"], icir, stat["icpos"] * 100))
print(" 多头(最高组): 年化超额 %+.1f%% | 最大回撤 %+.1f%% | 夏普 %.2f" % (
stat["top_ann"] * 100, stat["top_mdd"] * 100, stat["top_sharpe"]))
print(" 多空(高-低): 年化 %+.1f%% | 最大回撤 %+.1f%% | 夏普 %.2f" % (
stat["ls_ann"] * 100, stat["ls_mdd"] * 100, stat["ls_sharpe"]))=== 因子检验(预测目标=市场超额, 半年频) ===
[Topten_to_float_ashare(持仓/流通市值)]
RankIC 0.037 | ICIR 0.45 | IC>0占比 72%
多头(最高组): 年化超额 +3.0% | 最大回撤 -35.1% | 夏普 0.27
多空(高-低): 年化 +5.3% | 最大回撤 -28.7% | 夏普 0.48
[delta_to_float_ashare(环比变化)]
RankIC 0.037 | ICIR 0.61 | IC>0占比 82%
多头(最高组): 年化超额 +2.6% | 最大回撤 -38.7% | 夏普 0.24
多空(高-低): 年化 +5.2% | 最大回撤 -10.9% | 夏普 0.64
[Topten_count(重仓基金数)]
RankIC 0.019 | ICIR 0.16 | IC>0占比 61%
多头(最高组): 年化超额 +2.9% | 最大回撤 -19.8% | 夏普 0.37
多空(高-低): 年化 -1.1% | 最大回撤 -61.1% | 夏普 0.06
主因子分层超额净值
Topten_to_float_ashare(持仓/流通市值)的分层累计超额净值——高/低组分化在 2016 年后明显扩大,呼应报告「2017 年以来效果显著」。
python
nav, name = results["fac_tofloat"]
fig, ax = plt.subplots(figsize=(9.5, 5.2))
for q in [0, 2, 4, 6, 8, 9]:
lbl = "第%d组%s" % (q + 1, "(最高)" if q == 9 else "(最低)" if q == 0 else "")
ax.plot(nav[q], marker="o", ms=3, label=lbl)
ax.set_title("基金重仓持仓因子 分层超额净值\n%s(半年频)" % name)
ax.set_ylabel("累计超额净值"); ax.set_xlabel("期数"); ax.legend(fontsize=8); ax.grid(alpha=0.3)
plt.show()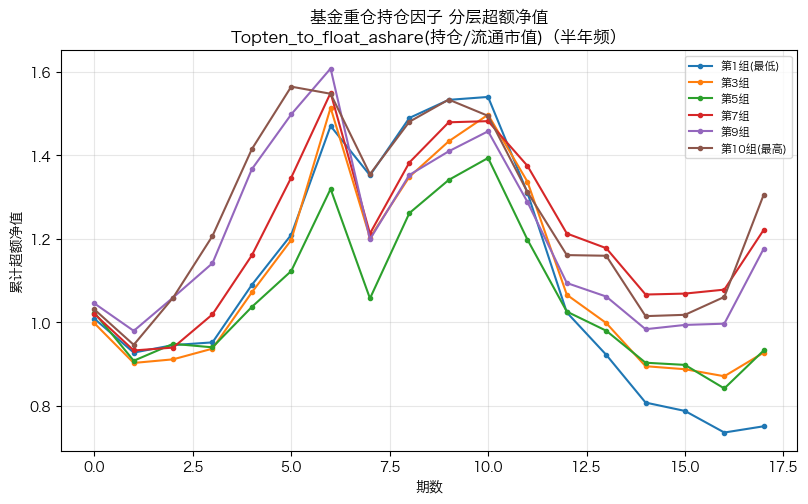
结论
- 持仓占流通市值比例(及其环比变化)对基金重仓股超额收益有正向预测力:IC 为正、IC>0 占比高、高组超额显著高于低组,与报告核心结论一致;
Topten_count较弱(亦同报告)。 - 与报告数值差异(ICIR 偏低)主要来自三处口径简化:市场超额 vs 残差收益、半年频 vs 月频、全样本 vs 业绩前 50% 基金子样本。
- 下一步(Phase 2):加
fund_nav做基金业绩筛选 → 在绩优基金重仓股中按持仓因子选 top-N 等权,复现「筛选股票池」超额净值;行业中性化逼近残差收益 + 改月频。